From RNN to Pointer Network
从基础的RNN网络结构开始,介绍LSTM、Encoder-Decoder、Attention Mechanism、Pointer Network。
RNNs
与传统的前向神经网络和卷积神经网络不同,循环神经网络 (Recurrent Neural Networks,RNNs) 是一种擅于处理序列数据的模型,例如文本、时间序列、股票市场等。
对于序列数据,输入之间存在着先后顺序,如“我打车去商场” 和 “我去商场打车”,我们通常需要按照一定的顺序阅读句子才能理解句子的意思。
参考自Afshine Amidi 和 Shervine Amidi 的 Recurrent Neural Networks cheatsheet[1]
面对这种情况我们就需要用到循环神经网络了,其结构如下:
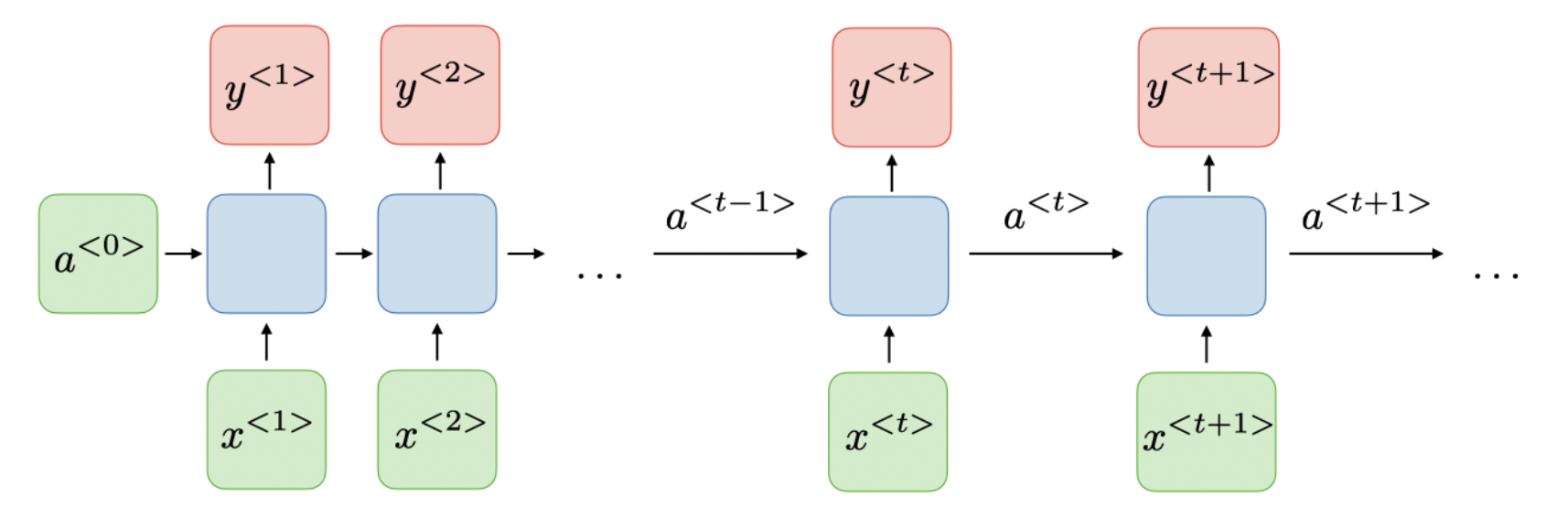
$x^{T}$为我们的输入序列,$a^{T}$为隐藏层输出,它保存了输入序列的历史信息,$y^{T}$为输出序列,计算方法如下
其中,$W_{ax}$,$W_{aa}$,$W_{ya}$,$b_a$,$b_y$,$W_{ax}$,$W_{aa}$,$W_{ya}$,$b_a$,$b_y$ 为模型参数,由所有时刻$t$共享, $g_1$,$g_2$ 为激活函数。
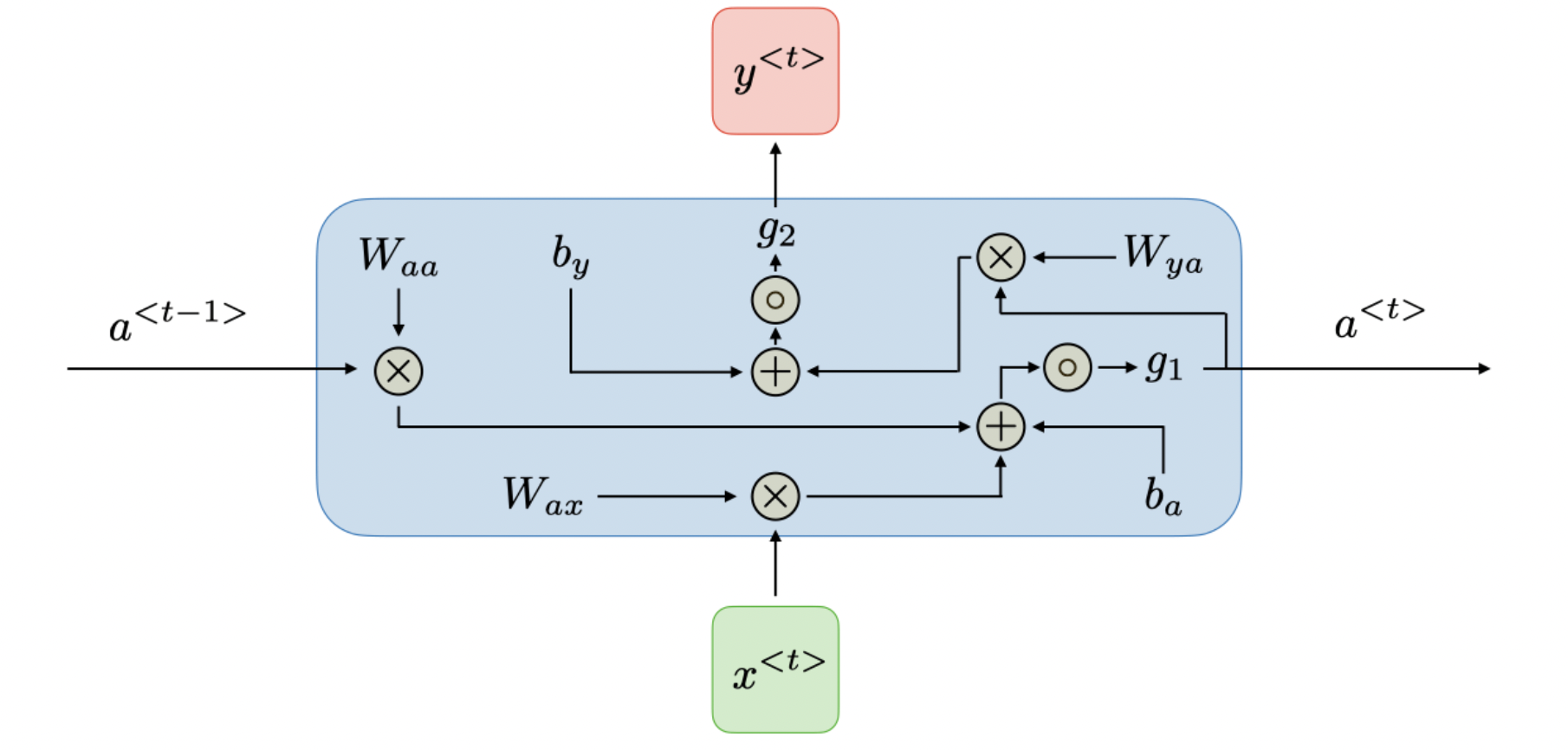
损失函数$\mathcal{L}$ 定义为各时刻$\mathcal{L}$ 之和,每一时刻$t$都将进行:计算loss,计算偏导数,更新网络参数
其中,$\hat{y}^{
这样一个基础的RNN结构,隐藏层的存在让他拥有“记忆”的能力,当然它也存在一些不足。
| 😆 | 😭 |
|---|---|
| 输入序列长度可变,模型size不会随着输入序列长度增加而增加 | 计算缓慢 |
| “记忆”历史信息 | 长期记忆能力不足 |
| 权重在任意时刻共享 | 看不到未来的信息 |
面对不同的应用场景,RNN拥有多种结构:
- 输入不是序列而输出为序列,如根据类别产生音乐
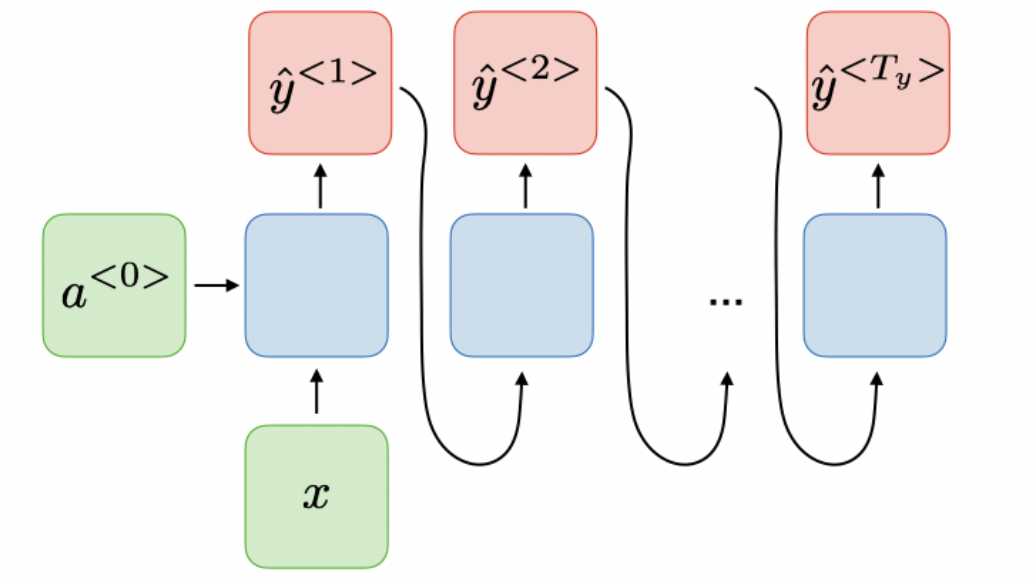
- 输入是序列而输出不是序列,如情感分析
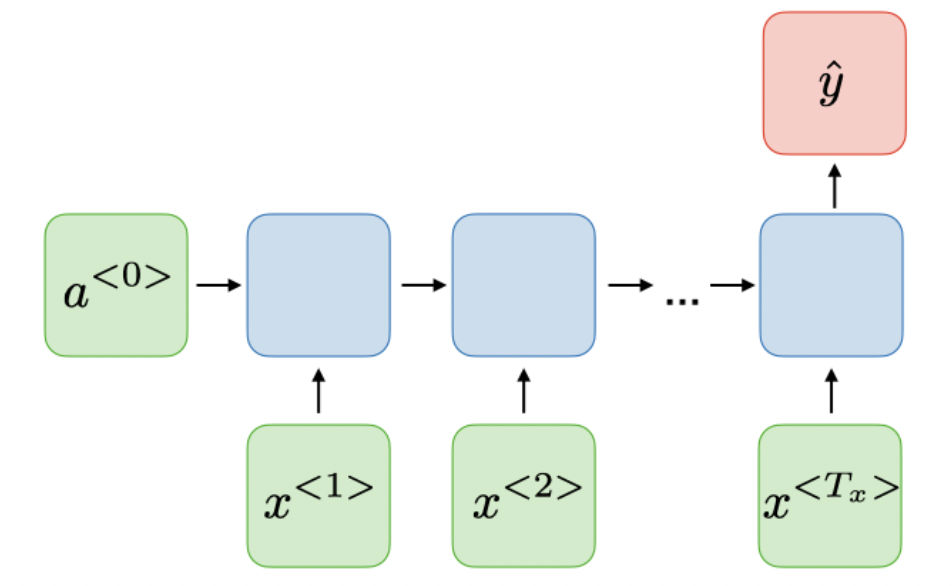
- 输入是序列而输出也是序列,且等长,传统RNN结构
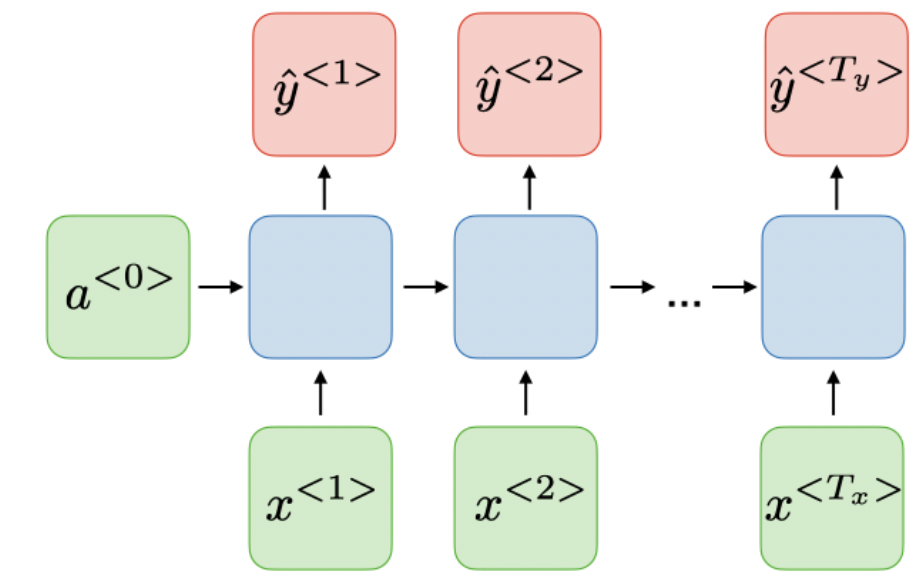
- 输入是序列而输出也是序列,且不等长,如下文我们提到的encoder-decoder模型seq2seq
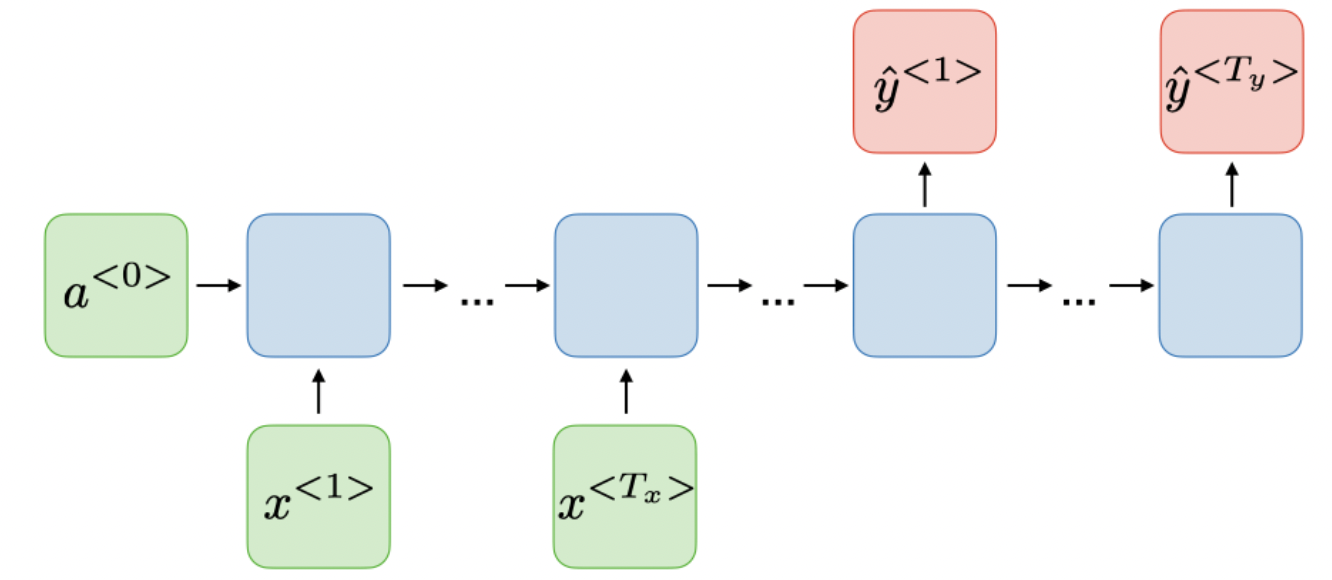
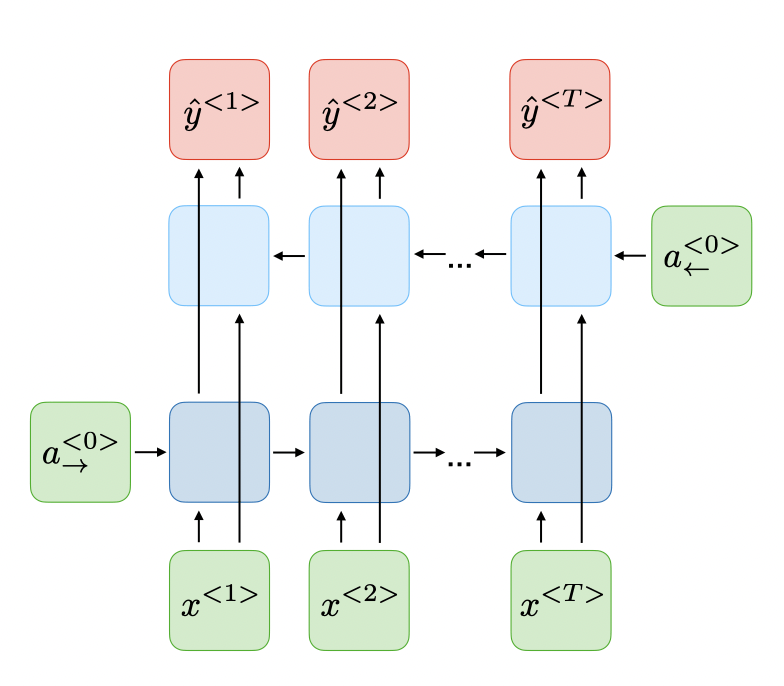
- 对原序列进行双向输入,可以获取“未来信息”、“过去信息”的Bidirectional (BRNN)
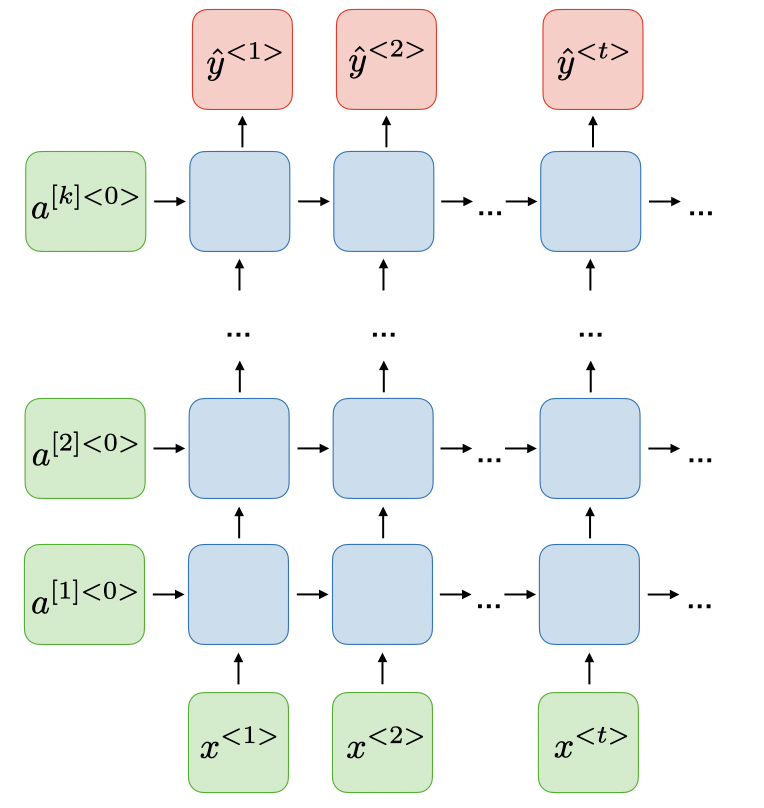
- 将RNN堆叠,可以处理更复杂问题的Deep (DRNN)
LSTM
RNN结构十分简单,但参数矩阵的梯度存在长期依赖,当面对一个长序列的时候,由于梯度消失/爆炸,RNN难以发挥作用。1997年,Hochreiter & Schmidhuber在“LONG SHORT-TERM MEMORY“[2]中提出一种RNN的变种LSTMs(Long Short Term Memory networks),尝试解决长期依赖的问题。
该部分的图出自Christopher Olah的Understanding LSTM Networks[3]
在传统RNN中,循环单元结构简单,只有一层网络层,如单层tanh层。
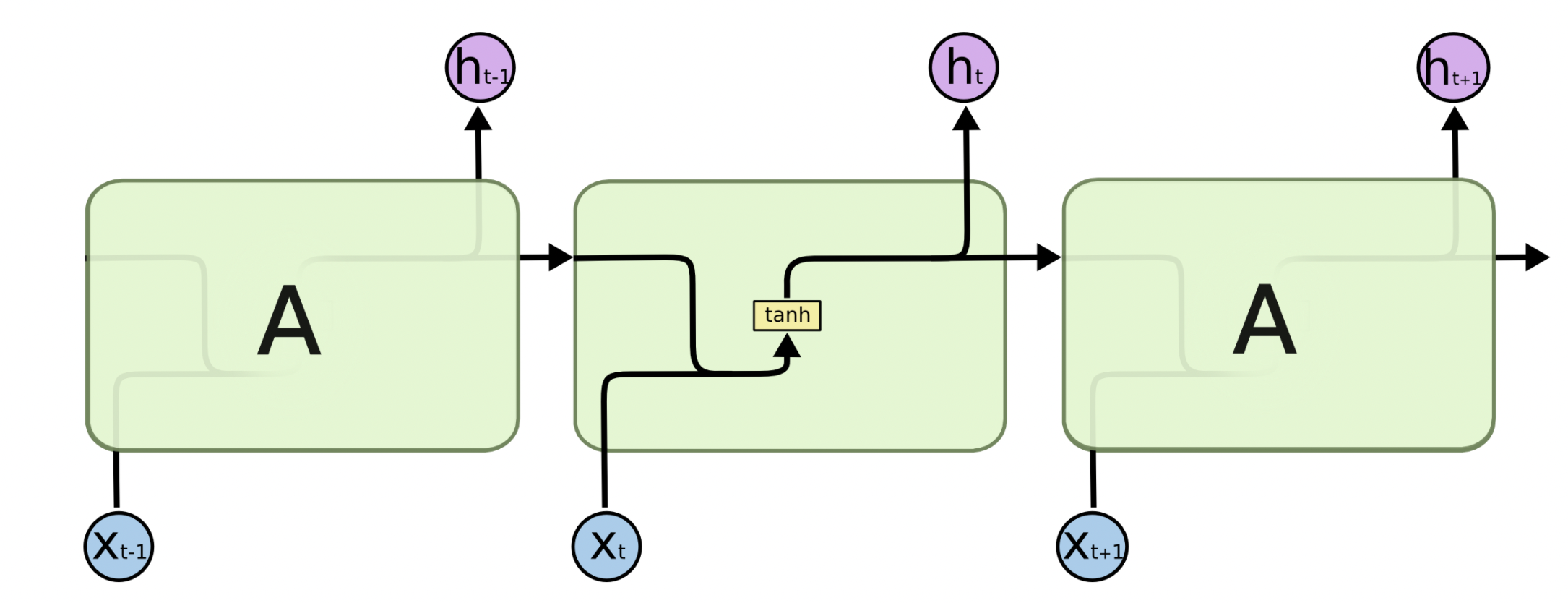
为了应对长期依赖,LSTM的循环单元结构更为复杂,他不再只有一层,取而代之的是多层神经网络层,他们各有不同的功能,且以特殊的方式互相连接在一起。
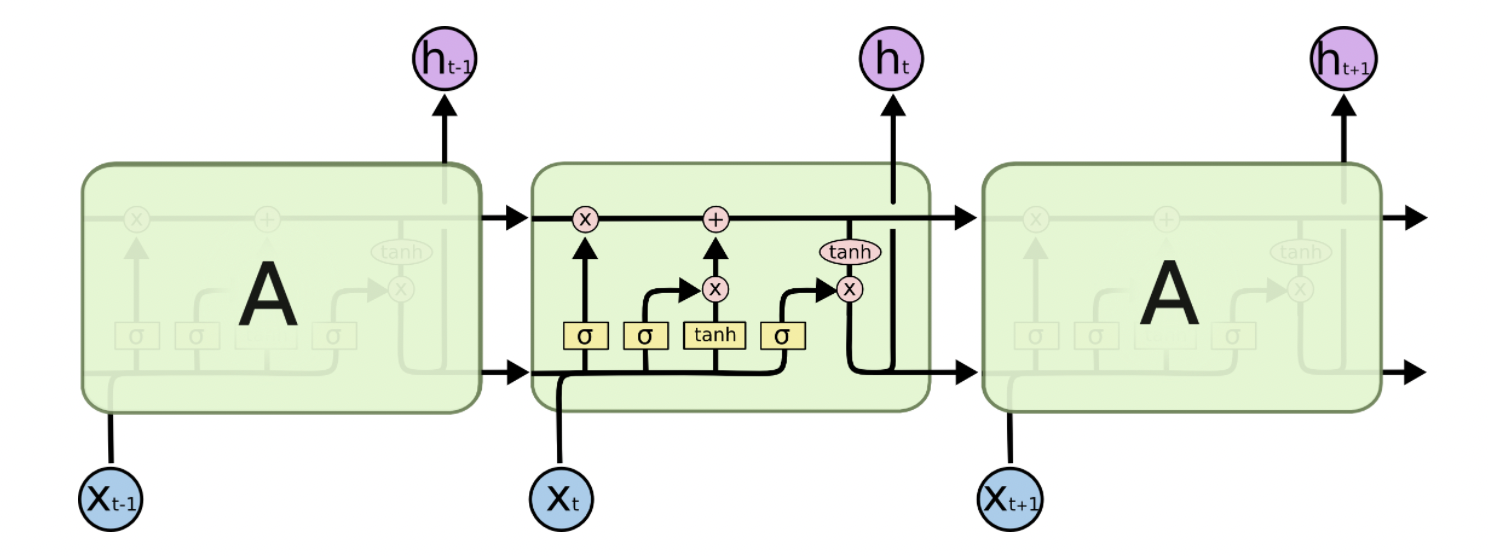
上图中的一些符号含义如下

带箭头的线代表向量的流动方向,分叉代表向量流向多个节点,合并代表向量以某种方式共同作用;黄色矩形代表神经网络层,拥有相应的权重、偏置、激活函数;粉色圆形代表一些向量运算,如按位乘等。
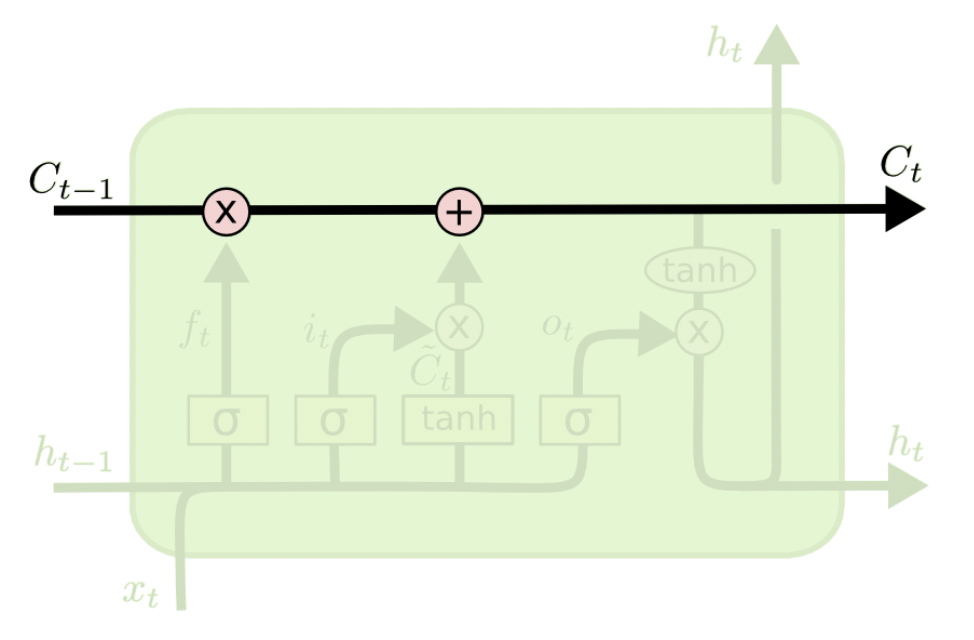
LSTMs的一个关键设计在于$C_t$的引入,他经过“遗忘门”、“输入门”的作用,最终在“输入门”影响最终的隐状态$h$。
另一关键设计是”门”的引入,他由sigmoid层与按位乘运算组成。LSTMs有三个门:遗忘门、输入门、输出门,我们来逐步了解他们是如何起作用的。
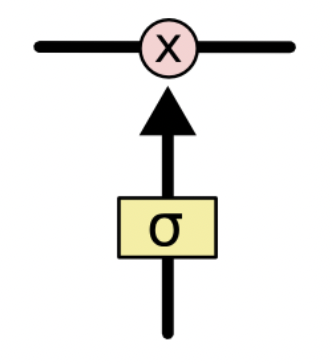
首先是遗忘门,用来判断哪些信息应该删除;其中$\sigma$表示激活函数$\text{sigmoid}$,$h_{t-1}$代表上一时刻隐状态,$x_t$代表当前时刻输入。
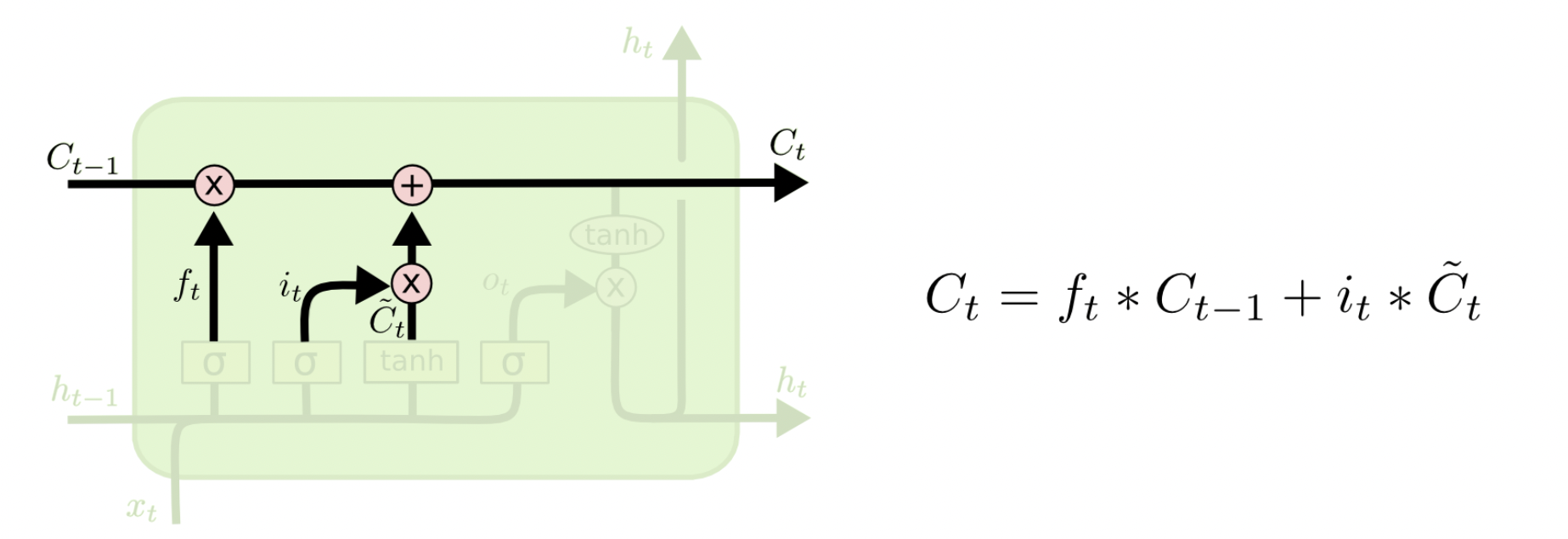
$h_{t-1}$、$x_t$ 经过激活函数后得到$f_t$,$f_t$中每一个值的范围都是 [0, 1]。$f_t$中的值越接近 1,表示对应位置的值更应该记住;越接近 0,表示对应位置的值更应该忘记。将 $f_t$与$C_{t-1}$按位相乘 (ElementWise 相乘) ,即可以得到遗忘无用信息之后的$C_{t-1}^{‘}$。
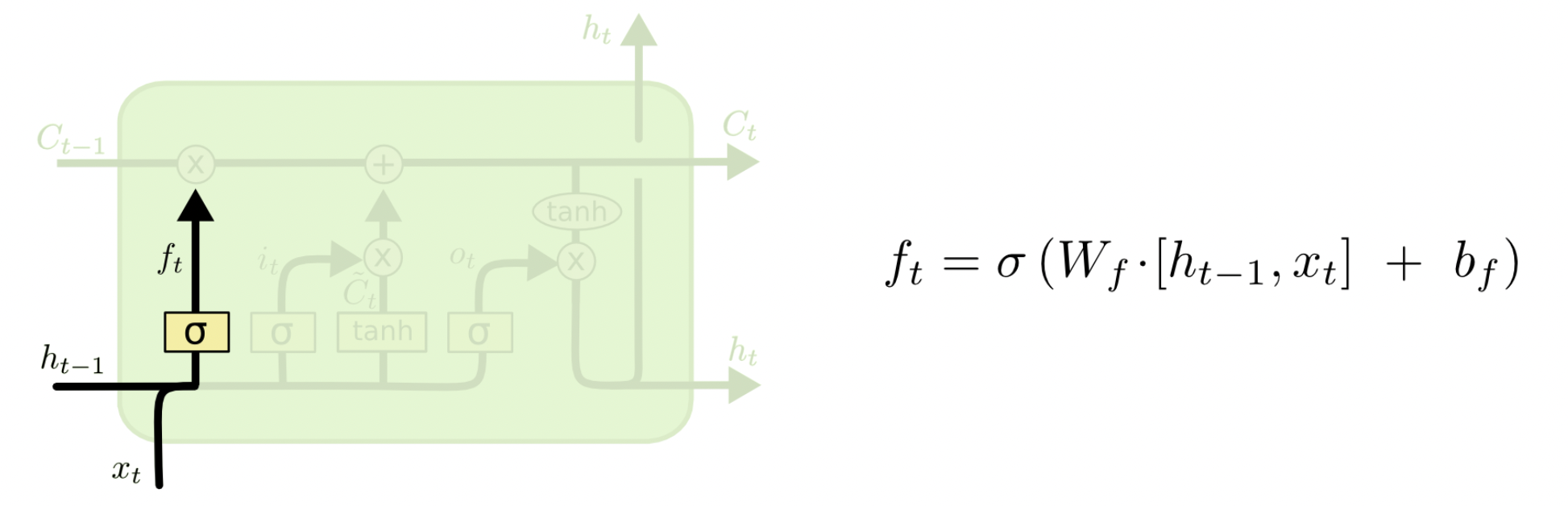
其次是输入门,用来判断哪些新的信息应该记住。$h_{t-1}$$、x_t$经过 tanh 激活函数可以得到新的输入信息$\tilde{C_{t}}$,但是这些新信息并不全是有用的,因此需要使用$h_{t-1}$和$x_t$经$\text{sigmoid}$得到 $i_t$,$i_t$表示哪些新信息是有用的。两向量相乘后的结果加到$C_{t-1}^{‘}$中,即得到$C_t$。
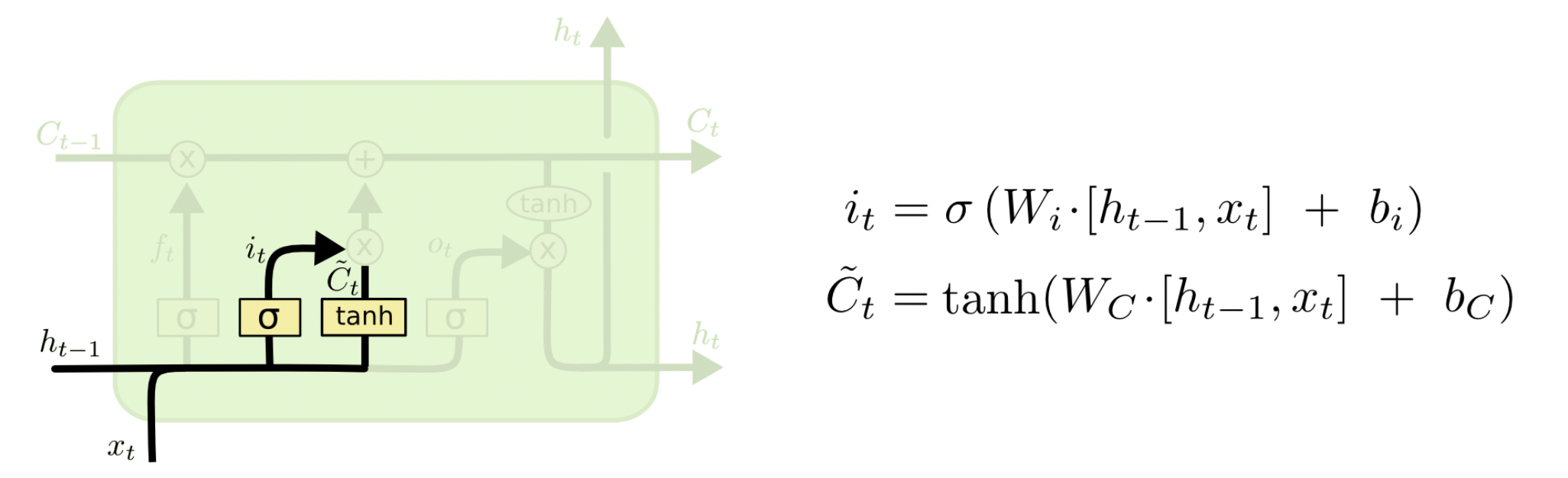
现在,我们已经知道如何更新$C$了
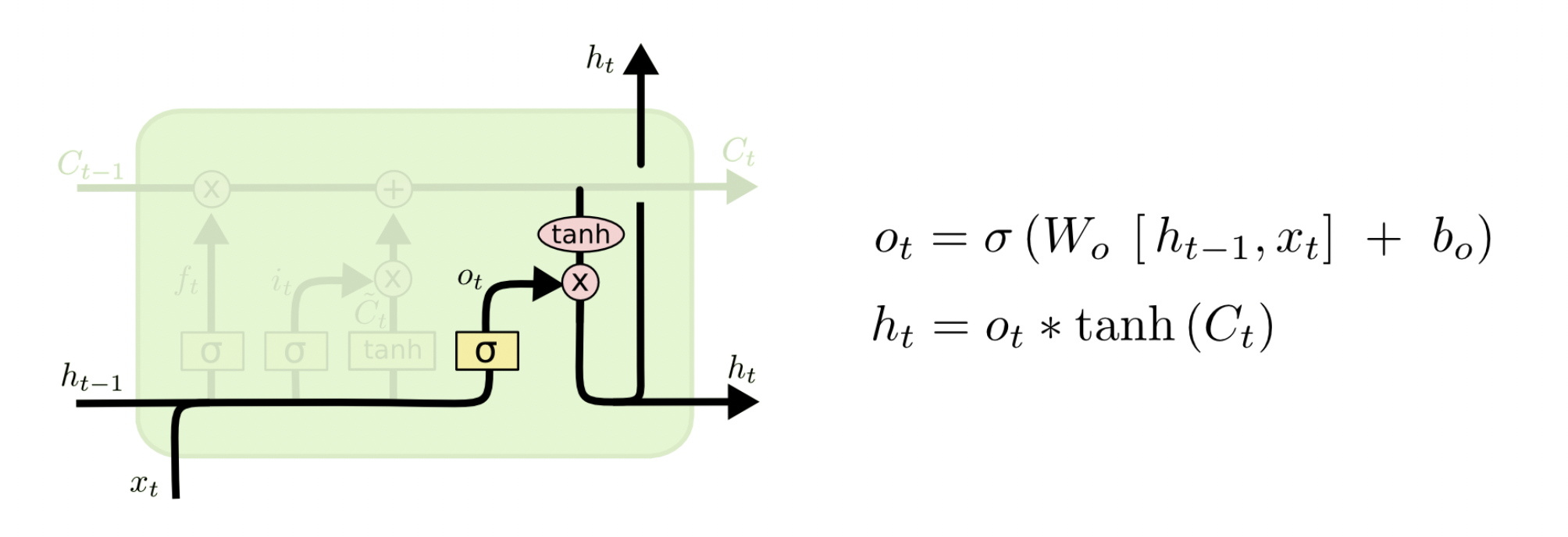
最后是输出门,用来判断应该输出哪些信息到$h_t$中。$C_t$经过 tanh 函数(范围变为[-1, 1])得到应该输出的信息,然后$h_{t-1}$和$x_t$经过 sigmoid 函数得到一个向量$o_t$ (范围[0, 1]) ,表示哪些位置的输出应该去掉,哪些应该保留。两向量相乘后的结果就是最终的$h_t$。
Attention Mechanism
Encoder-Decoder概念
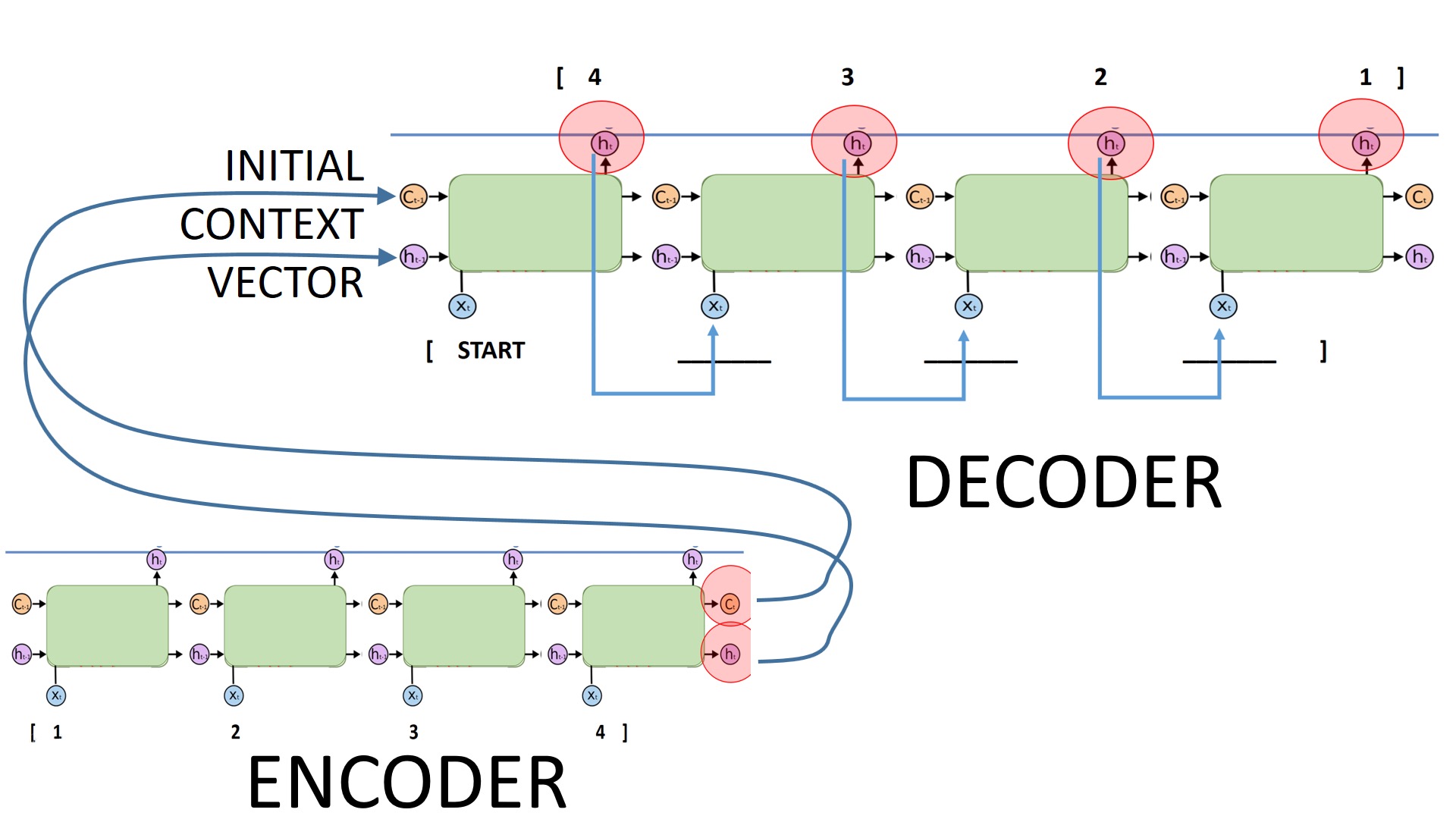
Encoder-Decoder结构是为了解决序列问题提出的,它将整个网络模型分为Encoder和Decoder两部分:编码器将输入序列转化成定长的中间语义向量,解码器将之前中间语义向量转化为输出序列。
基于此结构,产生了许多经典的模型。如2014年Sutskever等人在Sequence to Sequence Learning with Neural Networks[4]一文中提出的Seq2Seq模型 (同年份Yoshua Bengio团队的Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation[5]也独立的阐述了Seq2Seq的主要思想) ,Google 在2017年提出的Transformer模型等。
该部分参考自Natural Language Processing with Deep Learning[6]及Murat Karakaya的SEQ2SEQ LEARNING[7]
接下来以Seq2Seq模型为例,简单介绍一下Encoder与Decoder是如何工作的。
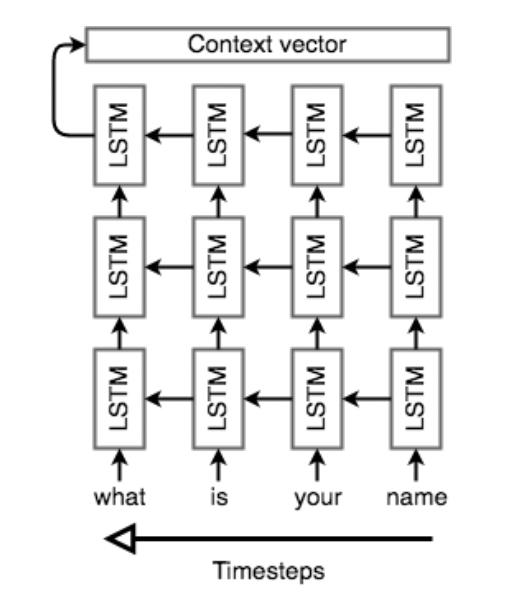
Encoder需要接收输入序列,产生中间语义向量$\text{Context vector}$ (简记为$C$),但是将一个任意长度的输入序列转换为固定长度的$C$对于单层架构来说太困难了,通常我们会使用多层 (DRNN),图中展示的是三层LSTMs架构,最后我们使用Encoder的全部隐状态作为$C$。
此外,Seq2Seq通常会逆序输入原序列 (注意图中Timesteps的箭头指向) ,这样一来,Encoder最后的输出将会是原序列的首个元素,D ecoder在解码过程中遇到的首个输入正好对应原序列的首元素。这对最终结果是有利的,如文本任务,当Decoder正确翻译了前面一部分单词,将很容易猜出完整的句子。
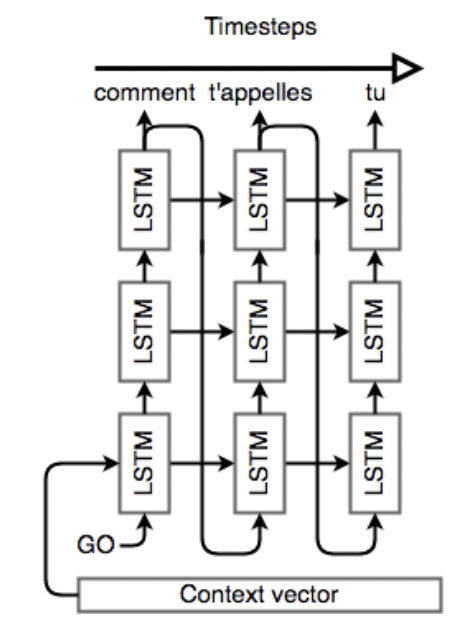
Decoder同样是一个LSTM多层网络,但结构更复杂一些,每一层的输出将作为下一层的输入。使用Encoder中得到的相关信息初始化Decoder,并输入一个开始信号(在文本任务中,通常为<EOS>),最终得到输出序列,输入序列和输出序列长度不要求相同。
得到输出序列后,我们可以定义$\text{loss}$,使用梯度下降和后向传播最小化$\text{loss}$,训练我们的。Seq2Seq模型。
Attention-based Models
一个句子中不同的单词,给予的关注度是不同的,如“the ball is on the field”,你会更关注”ball,” “on,” 和”field,”。因此, Bahdanau等人提出了一种解决方案[8],其中设计的关键一点便是Attention机制。
Minh-Thang Luong等人的Effective Approaches to Attention-based Neural Machine Translation对Attention Mechanism做了很好的总结,以下内容参考于此[9]
Attention Mechanism可分为:关注所有源词的全局方法 (global) 和只关注源词子集的局部方法 (local),两种方法的基本思想都是模拟Attention机制,获得当前 $t$ 时刻对齐 (修正) 后的$\text{Context vector}$,即 $c_t$ ,使用该$c_t$计算输出,隐状态等。
这里只对接下来Ptr Net复现将要使用的global方法做一个简要介绍。
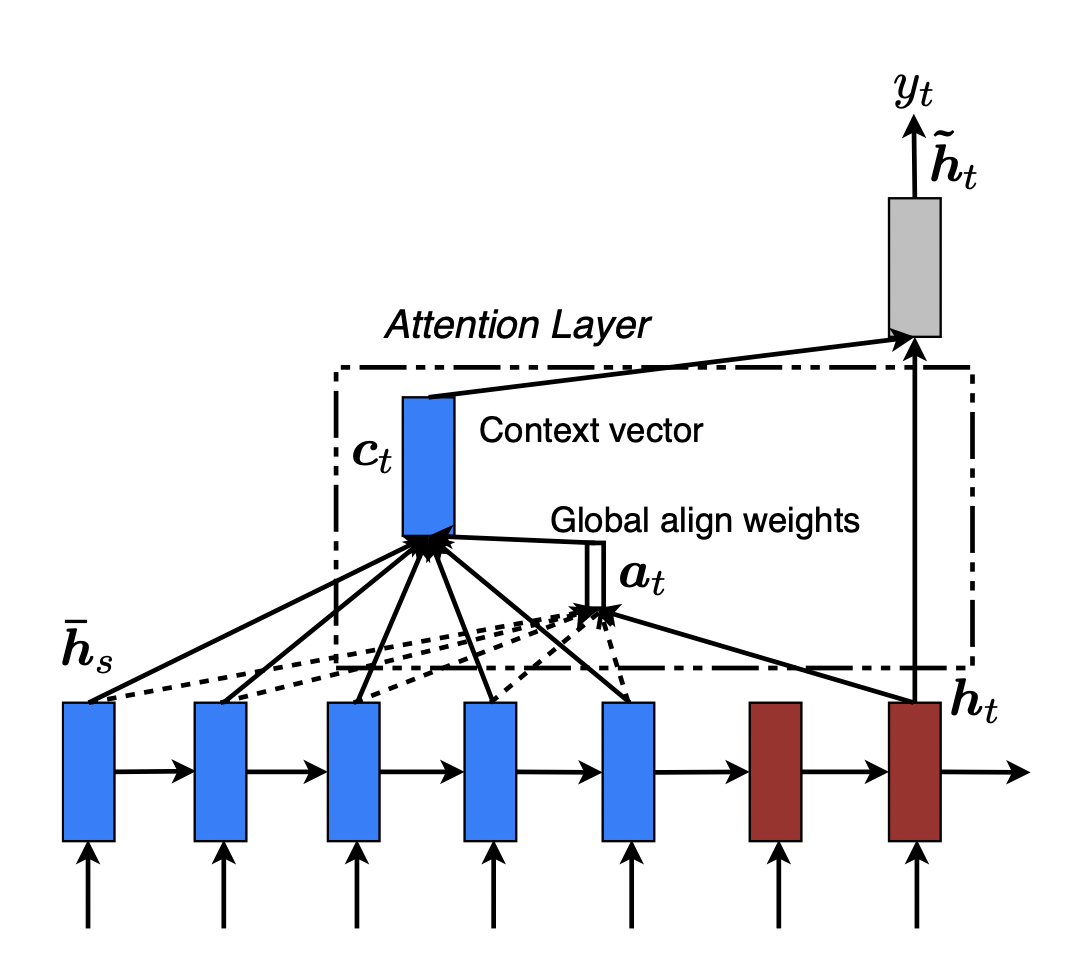
一个Seq2Seq模型,分为两部分:encoder (蓝) 和 decoder (红) 。Attention-based Model希望在每一个输出时刻$j$,获得一个对应的score,评估Encoder $i$ 位置的输入与此刻的相关程度,基于此对原本的中间语义向量进行一个修正。通俗点说,Attention Layer将encoder的隐状态按照一定权重加和之后拼接到decoder的隐状态上,以此作为额外信息,起到“软对齐”的作用,并且提高了整个模型的预测准确度。
简单举个例子,在机器翻译中一直存在对齐的问题,也就是说源语言的某个单词应该和目标语言的哪个单词对应,如“Who are you”对应“你是谁”,如果我们简单地按照顺序进行匹配的话会发现单词的语义并不对应,显然“who”不能被翻译为“你”。
而Attention机制非常好地解决了这个问题,如前所述,Attention会给输入序列的每一个元素分配一个权重,如在预测“你”这个字的时候输入序列中的“you”这个词的权重最大,这样模型就知道“你”是和“you”对应的,从而实现了软对齐。
具体计算过程如下:
设编码器隐藏层所有隐状态为 $\bar{h}_s$ ,当前第 $j$ 个输出时刻,decoder单元隐状态为 $h_t$,score的计算有三种方式可选择:
接下来根据score计算我们当前时刻的的对齐向量 $a_t(s)$,他的长度随输入序列长度变化而变化:
最后,根据原$\text{Context vector}$ (即Encoder所有隐状态$\bar{h}_s$),$a_t(s)$获得对齐后的$c_t$,
Decoder最终的隐状态依据$c_t$产生,
Pointer Network
为了解决输出序列长度不固定,随输入序列变化而变化的问题 (如组合优化问题) ,2015年,Vinyals 等人对Seq2Seq中的Attention机制进行了改进,提出了指针网络模型 (Pointer Network, Ptr-Net)[10],并展示了如何使用Ptr-Net求得三种几何问题 (凸包问题,计算Delaunay三角形,TSP问题) 的近似解,文章中还表明,Ptr-Net面对测试集的表现并不局限训练模型,拥有良好的泛化能力。
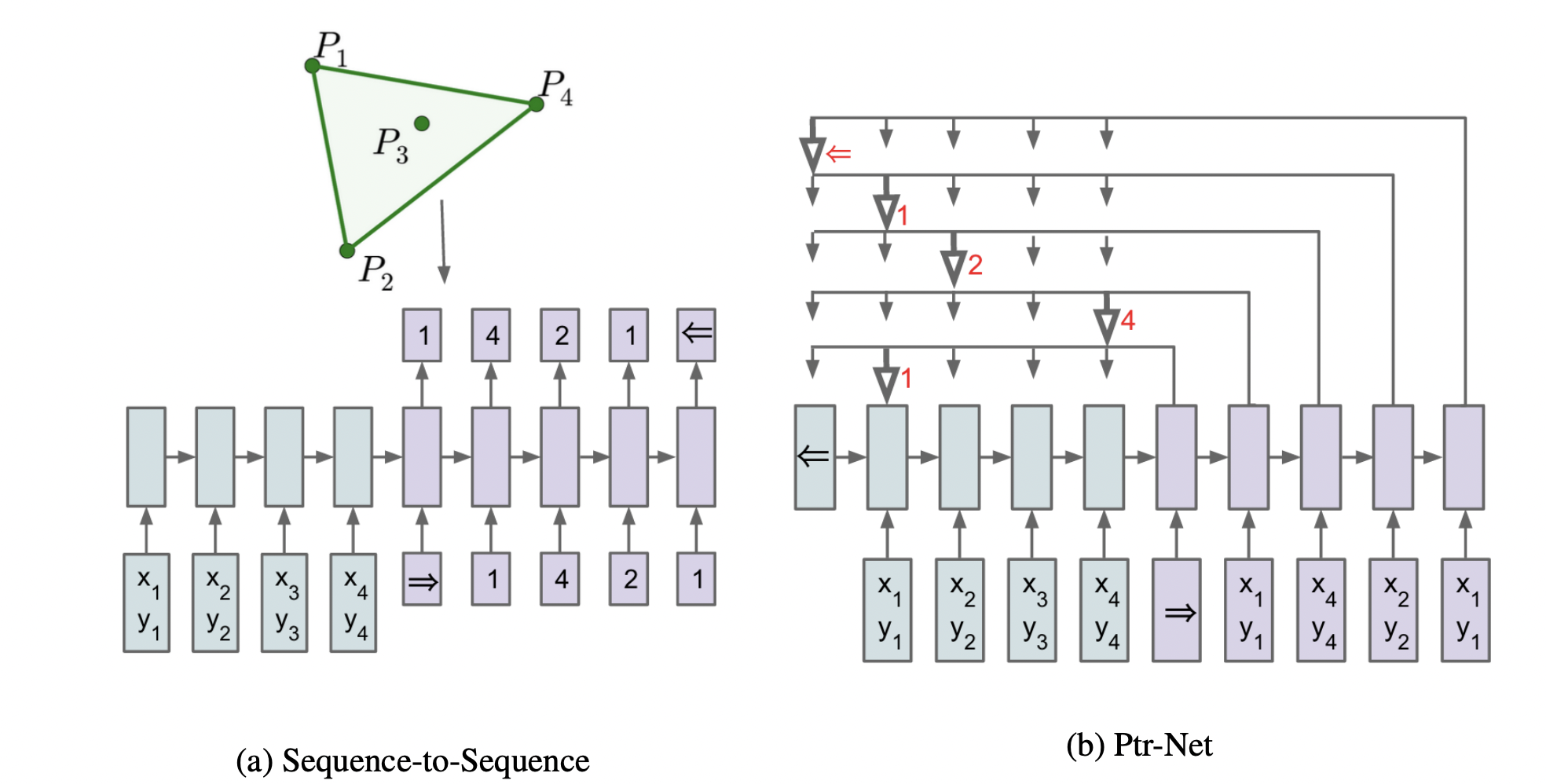
Ptr-Net的主要改进在于简化了Attention Mechanism;回顾上文Attention-based Models一节的计算过程,Ptr-Net直接将对齐向量$\alpha _{t}(s)$作为指向输入序列的概率数组,认为$\alpha _{t}(s)$最大值对应位置即为当前的指针指向;在TSP问题中,我们将城市坐标作为输入序列、最优解作为输出序列对模型进行训练,指针指向即为当前时刻应当访问的城市,Shir Gur的github项目PointerNet对PtrNet在该方面的应用做了很好的复现。
References
- Afshine Amidi,Shervine Amidi. Recurrent Neural Networks cheatsheet ↩
- Hochreiter S, J. Schmidhuber. Long short-term memory. Neural Computation 9.8(1997):1735-1780. ↩
- Christopher Olah.Understanding LSTM Networks ↩
- Sutskever I, Vinyals O, Le Q V. Sequence to Sequence Learning with Neural Networks[C]//Advances in neural information processing systems. 2014: 3104-3112. ↩
- Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014. ↩
- Guillaume Genthial, Lucas Liu, Barak Oshri, Kushal Ranjan. CS224n: Natural Language Processing with Deep Learning , 2017. ↩
- Murat Karakaya.SEQ2SEQ LEARNING. 2020. ↩
- Bahdanau D, Cho K, Bengio Y. Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate[J]. arXiv preprint arXiv:1409.0473, 2014. ↩
- Luong M T, Pham H, Manning C D. Effective Approaches to Attention-based Neural Machine Translation[J]. Computer ence, 2015. ↩
- Vinyals O, Fortunato M, Jaitly N. Pointer networks[J]. arXiv preprint arXiv:1506.03134, 201 ↩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!